[실기] - 데이터베이스 관계데이터베이스(ERD)
- 관계형 모델
- 튜플은 행으로 영어로는 Degree이며, 갯수는 차수
- 어트리뷰트는 속성이며, 영어로 Cardinarity로, 열의 갯수의 집합은 카디널리티
- 릴레이션(테이블)
- 릴레이션 스키마(구조)
- 릴레이션 인스턴스 : 저장된 데이터의 집합
- 관계 데이터 언어
- 관계대수 : 절차적 - 어떻게 찾을 것인지?
- 순수관계연산자
- 시그마(σ) : SELECT
- ^ == AND / V == OR
- σ 성적 ≥ 90 ^ 학과 ='컴퓨터과'(학생)
- 프로젝트(π) : PROJECT
- π 학생, 이름 (학생)
- π 학생, 이름 (σ 성적 ≥ 90 (학생))
- 조인(⋈) : JOIN
- (하생)⋈학번=학번(수강과목)
- 나누기(%) : DIVISION
- R%S1
- S1에 모든 조건이 충족하는 것만 추가해줌
- 밑에 이미지 참고해서 구해보기
- S1에 모든 조건이 충족하는 것만 추가해줌
- R%S1
- 시그마(σ) : SELECT
- 일반 집합 연산자
- U 합집합 : 중복제거 합치기
- ∩ 교집합 : 똑같은것만
- - 차집합 : 중복된거 제거
- 교차곱 : 2개 곱하기
- 순수관계연산자
- 관계해석 : 비절차적
- 무엇을 찾을지?
- 기호 종류
- ∀(모든 가능한 튜플)
- ∃(어떤 튜플 하나라도 존재)
- 기호 종류
- 무엇을 찾을지?
- 관계대수 : 절차적 - 어떻게 찾을 것인지?

[문제]
1. 업무 분석 결과로 도출된 실체와 실체 간의 관계를 도식화한 다이어그램
2. 하나의 릴레이션(테이블)을 구성하는 속성(열)의 전체 개수
3. 하나의 릴레이션(테이블)을 구성하는 튜플(행)의 전체 개수
일반적인 데이터 모델의 구성요소
4. 다음이 설명하는 관계대수 연산자의 기호를 쓰시오.
- 두 릴레이션 A, B에 대해 B 릴레이션의 모든 조건을 만족하는 튜플들을 릴레이션 A에서 분리해 내어 프로젝션 하는 여산
5. 테이블에서 특정 속성에 해당하는 열을 선택하는데, 사용되며 결과로는 릴레이션의 수직적 부분 집합에 해당하는 관계대수 연산자를 쓰시오.
6. 조건을 만족하는 릴레이션의 수평적 부분집합으로 구성하며, 행을 선택할때 사용하는 관계 대수연산자를 쓰시오.
7. 관계대수 연산에서 두 릴레이션의 공통으로 가지고 있는 속성을 이용하여 두 개의 릴레이션을 하나로 합쳐서 새로운 릴레이션을 만드는 연산자를 쓰시오.
[문01~04] 다음 고객 릴레이션에 대한 관계대수를 작성하시오
<<고객>>
| 고객아이디 | 이름 | 나이 | 등급 | 직업 |
| hoho | 이순신 | 29 | gold | 교사 |
| grace | 홍길동 | 24 | gold | 학생 |
| mango | 삼돌이 | 27 | silver | 학생 |
| juce | 갑순이 | 31 | gold | 공무원 |
| orange | 강감찬 | 23 | silver | 군인 |
Q 01) 고객 릴레이션에서 등급이 gold인 고객들을 검색하는 관계대수를 작성하시오.
A) σ 등급 = 'gold' (고객)
Q 02) 고객 릴레이션에서 등급이 gold이고 나이가 25 이상인 고객들을 검색하는 관계대수를 작성하시오.
A) σ 등급 = 'gold' ∧ 나이 ≥ 25 (고객)
Q 03) 고객 릴레이션에서 고객아이디와 등급을 가져오는 관계대수를 작성하시오.
A) π 고객아이디, 등급 (고객)
Q 04) 고객 릴레이션에서 등급이 gold인 고객의 고객 아이디와 등급을 가져오는 관계대수를 작성하시오.
A) π 고객아이디, 등급(σ 등급 = 'gold' (고객))
Q 05) 다음 SQl 문장과 동일한 관계대수를 작성하시오.
| SELECT SNO, NAME FROM STUDENT WHERE AGE >20; |
A) π SNO, NAME (σ AGE > 20 (STUDENT))
Q 06) 다음 SQL 문장과 동일한 관계대수를 작성하시오.
| SELECT SNO, NAME FROM T1, T2 ON T1.SNO = T2.SNO |
A) π SNO, NAME(T1 ⋈ T1.SNO = T2.SNO T2)
해설)
SELECT SNO, NAME, SELECT SNO, NAME -> T1 ⋈ T1.SNO = T2.SNO T2
SELECT SNO, NAME -> SELECT SNO, NAME
Q 07) 다음 관계대수식을 적용한 결과를 작성하시오.
<<직원>>
| 직원번호 | 이름 | 부서 |
| 10 | 김 | B20 |
| 20 | 이 | A10 |
| 30 | 박 | A10 |
| 40 | 최 | C30 |
<<부서>>
| 부서번호 | 부서명 |
| A10 | 기획 |
| B20 | 인사 |
| C30 | 총무 |
<<정책>>
| 정책번호 | 정책명 | 제안자 |
| 100 | 인력양성 | 40 |
| 200 | 주택자금 | 20 |
| 300 | 친절교육 | 10 |
| 400 | 성과금 | 10 |
| 500 | 신규고용 | 20 |
| π 이름, 부서명, 정책명 (부서 ⋈ 부서번호 = 부서(π 정책명, 이름, 부서 (정책 ⋈ 제안자 = 직원번호 직원))) |
A)
| 이름 | 부서명 | 정책명 |
| 최 | 총무 | 인력양성 |
| 이 | 기획 | 주택자금 |
| 김 | 인사 | 친절교육 |
| 김 | 인사 | 성과금 |
| 이 | 기획 | 신규고용 |
해설)
안에서 부터 처리한다.
(π 정책명, 이름, 부서 (정책 ⋈ 제안자 = 직원번호 직원))
출력할 속성은 정책명, 이름, 부서이고 정책 테이블과 직원 테이블을 제안자 = 직원번호로 JOIN한다.
결과 테이블은 다음과 같다.
| 정책명 | 이름 | 부서 |
| 인력양성 | 최 | C30 |
| 주택자금 | 이 | A10 |
| 친절교육 | 김 | B20 |
| 성과금 | 김 | B20 |
| 신규고용 | 이 | A10 |
아직 관계대수가 남았으니 마저 처리한다.
| π 이름, 부서명, 정책명 (부서 ⋈ 부서번호 = 부서 [아까 연산한 테이블]) |
아까 처리한 것과 같은 형태이다.
출력할 속성은 이름, 부서명, 정책명이고 부서 ⋈ 부서번호 = 부서 [아까 연산한 테이블]를 JOIN 연산하면 최종 결과값이 나온다.
| 이름 | 부서명 | 정책명 |
| 최 | 총무 | 인력양성 |
| 이 | 기획 | 주택자금 |
| 김 | 인사 | 친절교육 |
| 김 | 인사 | 성과금 |
| 이 | 기획 | 신규고용 |
수학 연산과 같이 가장 안쪽에 있는 것부터 처리해 주고 그 결과값을 다시 처리해주면 된다.
Q 08 아래의 R과 S, 두 릴레이션ㅇ네 대한 R÷S의 결과와 DIVISION 연산의 정의를 작성하시오.
<>
| D1 | D2 | D3 |
| a | 1 | A |
| b | 1 | A |
| a | 2 | A |
| c | 2 | B |
<>
| D2 | D3 |
| 1 | A |
A)
DIVISION 연산의 정의 : 릴레이션 S의 조건에 만족하는 릴레이션 R에서 튜플을 분리하는 관계대수
R÷S :
| D1 |
| a |
| b |
해설)
DIVISION 연산의 정의 :
R÷S : divison 연산 R의 속성에서 S의 속성값을 모두 가진 튜플을 구하고 출력은 S가 가진 속성을 제외하고 한다.
S의 속성을 모두 가진 튜플은 R 속성 D1에서 a, b이다. S가 가진 속성 D2, D3를 제외하고 출력한 값은 다음과 같다.
| D1 |
| a |
| b |
Q 09 다음의 릴레이션 R1과 R2에 대한 관계대수 R1 ÷ R2의 결과 릴레이션을 작성하시오.
<>
| C1 | C2 |
| 1 | A |
| 2 | C |
| 1 | E |
| 1 | B |
| 3 | J |
| 4 | R |
| 3 | B |
| 2 | B |
| 5 | R |
| 3 | A |
| 4 | A |
<>
| C2 |
| A |
| B |
A)
| C1 |
| 1 |
| 3 |
해설)
관계대수 R1 ÷ R2한다는 것은 R1을 R2로 DIVISION 연산한다는 것이다. R1의 속성에서 R2의 속성값을 모두 가진 튜플을 구하고 출력은 R2가 가진 속성을 제외하고 한다.
R1에서 R2 속성 C2의 A, B를 둘다 가진 튜플은 C1이 1, 3인 튜플이다. R2의 속성을 제외하면 답은
| C1 |
| 1 |
| 3 |
가 된다.
Q 10 관계해석 연산자
A)
| 구분 | 기호 | 설명 |
| 연산자 | V | - OR 연산 |
| ∧ | - AND 연산 | |
| ㄱ | - NOT 연산 | |
| 정량자 | ∀ | - 모든 가능한 튜플 "For All" |
| ∃ | - 어떤 튜플 하나라도 존재 |
관계대수에 대한 다음 설명에서 괄호(①~⑤)에 들어갈 알맞은 용어를 쓰시오.
| · 관계대수는 관계형 데이터베이스에서 원하는 정보와 그 정보를 검색하기 위해서 어떻게 유도하는가를 기술하는 절차적인 언어이다. 관계대수에 사용되는 연산은 다음과 같다. · 합집합(UNION)은 두 릴레이션에 존재하는 튜플의 합집합을 구하되, 결과로 생성된 릴레이션에서 중복되는 튜플은 제거되는 연산으로, 사용하는 기호는 ( ① )이다. · 차집합(DIFFERENCE)은 두 릴레이션에 존재하는 튜플의 차집합을 구하는 연산으로, 사용하는 기호는 ( ② )이다. · 교차곱(CARTESIAN PRODUCT)은 두 릴레이션에 있는 튜플들의 순서쌍을 구하는 연산으로, 사용하는 기호는 ( ③ )이다. · 프로젝트(PROJECT)는 주어진 릴레이션에서 속성 리스트(Attribute List)에 제시된 속성 값만을 추출하여 새로운 릴레이션을 만드는 연산으로, 사용하는 기호는 ( ④ )이다. · 조인(JOIN)은 공통 속성을 중심으로 두 개의 릴레이션을 하나로 합쳐서 새로운 릴레이션을 만드는 연산으로, 사용하는 기호는 ( ⑤ )이다. |
관계대수는 관계형 데이터베이스에서 원하는 정보를 얻기 위해 데이터를 어떻게 유도할 것인가를 기술하는 절차적인 언어입니다. 관계대수에서 사용되는 연산과 그 기호는 다음과 같습니다:
- 합집합(UNION): 두 릴레이션에 존재하는 튜플의 합집합을 구하며, 결과 릴레이션에서 중복되는 튜플은 제거됩니다. 사용하는 기호는 **∪**입니다.
- 차집합(DIFFERENCE): 두 릴레이션에 존재하는 튜플의 차집합을 구하는 연산으로, 사용하는 기호는 **−**입니다.
- 교차곱(CARTESIAN PRODUCT): 두 릴레이션에 있는 튜플들의 순서쌍을 구하는 연산으로, 사용하는 기호는 **×**입니다.
- 프로젝션(PROJECT): 주어진 릴레이션에서 속성 리스트에 제시된 속성 값만을 추출하여 새로운 릴레이션을 만드는 연산으로, 사용하는 기호는 π입니다.
- 조인(JOIN): 공통 속성을 중심으로 두 개의 릴레이션을 하나로 합쳐서 새로운 릴레이션을 만드는 연산으로, 사용하는 기호는 **⋈**입니다.
이러한 연산들을 통해 관계형 데이터베이스에서 다양한 데이터 조작과 질의가 가능합니다.
연산은 원하는 데이터를 얻기 위해 릴레이션에 필요한 처리 요구를 수행하는 것으로 대표적으로 (가)와 (나)가 있다. 해당하는 것을 쓰시오.
| (가) : 원하는 결과를 얻기 위해 데이터의 처리 과정을 순서대로 기술(절차 언어) |
| (나) : 원하는 결과를 얻기 위해 처리를 원하는 데이터가 무엇인지만 기술(비절차 언어) |
(가) : 관계 대수
(나) : 관계 해석
관계 대수와 관계 해석은 상용화된 관계 데이터베이스에서는 실제로 사용되지 않는 개념적 언어다. 하지만 새
로운 데이터 언어가 제안되면 해당 데이터 언어의 유용성을 검증해야 하는데 검증의 기준 역할을 하는 것이
관계 대수와 관계 해석이다.
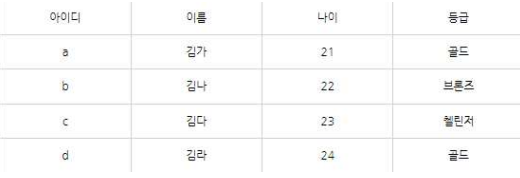
16. 아래 릴레이션에서 등급 속성을 𝝅한 결과 릴레이션을 나타내시오.
(머릿속으로 생각해보고 답을 확인하세요)
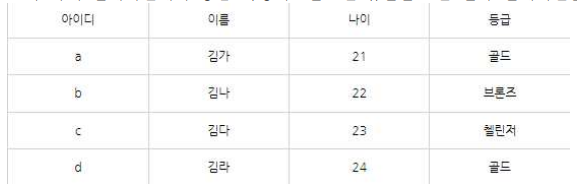
17. 아래 릴레이션에서 등급 속성이 골드인 튜플을 σ한 결과 릴레이션을 나타내시오.
(머릿속으로 생각해보고 답을 확인하세요)

18. 아래 2개의 릴레이션을 ⋈한 결과 릴레이션을 나타내시오.

(머릿속으로 생각해보고 답을 확인하세요)

19. 아래 주문내역 릴레이션을 제품1, 제품2와 각각 ÷한 결과 릴레이션을 나타내시오.

(머릿속으로 생각해보고 답을 확인하세요)

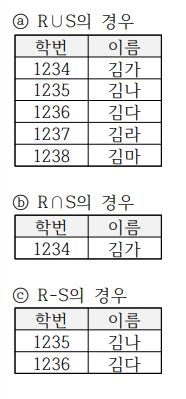
20. 두 릴레이션을 각각 R∪S, R∩S, R-S했을 때 결과 릴레이션을 나타내시오

(머릿속으로 생각해보고 답을 확인하세요)